Timescaledb를 적용하면서 1분, 1시간, 1일 통계 데이터 조회를 어떻게 해야 성능이 좋을지 고민을 했다.
첫 번째는 1분, 1시간, 1일 통계 데이터를 내서 별도의 테이블에 insert를 하는 방법이다. 이전에 사용하던 방식이라 로직을 크게 수정할 필요는 없었다. 하지만 수집되는 데이터 양이 많아서 동시에 같은 테이블을 insert를 하고 web에서는 select를 하게 되면 속도가 엄청 느려졌다.
두 번째 방법으로는 Materialized view를 활용하는 것이다. 통계 데이터 조회 속도를 높이기 위해 time_bucket을 사용해 Materialized View를 생성한다.
View는 알고 있었지만 Materialized View를 처음 알게 돼서 정리해보려고 한다.
(이 포스팅에서 Materialized View를 MView라고 부르려 한다.)
View와 Materialized View 차이
| View | Materialized View |
| 논리적으로 존재하는 테이블 | 물리적으로 존재하는 테이블 |
| View 호출시 쿼리를 조회하는 형식 | Materialized View 내부의 쿼리를 미리 실행해서 물리적인 테이블을 가지고 있음. -> 미리 만들어진 테이블에서 조회하는 형식 |
| 장점 - 실시간으로 데이터를 가지고 올 수 있다. |
장점 - 물리적인 테이블에서 조회하기 때문에 속도가 빠르다. - 인덱스를 설정할 수 있다. |
| 단점 - 인덱스를 생성할 수 없다. |
단점 - 데이터 싱크를 맞춰줘야 한다. -> 이미 조회된 쿼리이기 때문에 실시간으로 데이터를 보고 싶으면 추가적인 작업이 필요하다. |
MView는 메모리에 별도로 조회된 쿼리의 결과를 저장해 놓기 때문에, 조회 시 속도가 빠른 장점이 있다. 그리고 인덱스도 추가로 설정할 수 있어서 쿼리 속도를 개선할 수 있다는 장점이 있다.
하지만, 별도로 수동이든 자동이든 MView를 갱신시켜줘야 한다.
MView를 데이터를 업데이트 하는 방법을 알아보자.
Postgresql에서 MView 데이터 업데이트 방법
MView에 데이터를 갱신하려면 아래와 같이 REFRESH 문을 사용한다.
REFRESH MATERIALIZED VIEW table_name
데이터를 갱신할 때, PostgreSQL은 전체 테이블을 잠그므로 해당 테이블을 사용할 수가 없습니다. 이를 방지하기 위해 아래와 같이 CONCURRENTLY 옵션을 사용하면 된다. (CONCURRENTLY은 PostgreSQL 버전 확인 후 사용)
REFRESH MATERIALIZED VIEW CONCURRENTLY view_name;
Timescaledb에서 MView 생성 및 데이터 업데이트 방법
1. MView 생성
우선 아래와 같이 MView를 생성한다. 이때 time_bucket을 활용하는데 hyper table일 경우만 가능하다. hyper table의 파티셔닝 칼럼을 time_bucket에 설정해 주면 된다. 아래 예시에서는 "data_date" 칼럼이다.
CREATE MATERIALIZED VIEW mv_minute WITH (timescaledb.continuous) as
SELECT time_bucket('1 minute', data_date) as stats_date,
sum(a100.data_value) AS data_sum,
max(a100.data_value) AS data_max,
min(a100.data_value) AS data_min,
count(*) AS data_cnt,
first(data_date, data_date) as frist_data_date,
last(data_date, data_date) as last_data_date
FROM h_raw_data a100
GROUP BY stats_dt;
- - Index 생성
CREATE INDEX on mv_minute(stats_date, user_id);
만든 mv_minute를 아래 쿼리로 조회하게 되면 1분 통계 데이터를 얻을 수 있다.
select * from mv_minute order by stats_date;
stats_date : 1분 단위 시간
data_sum : 1분 범위의 합계
data_max : 1분 범위의 최대값
data_min : 1분 범위의 최소값
data_cnt : 1분 범위의 총 개수
first_data_date : 1분 범위의 시작 시간
last_data_date : 1분 범위의 마지막 시간

2. MView 데이터 업데이트
1) 수동으로 데이터 update ( refresh_continuous_aggregate )
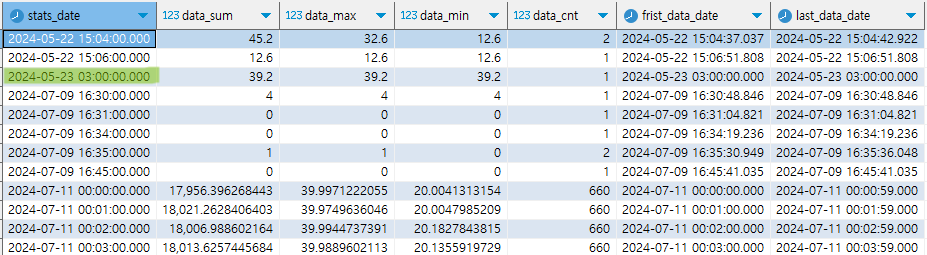
2024-05-23 데이터가 추가됬을 때, mv_minute를 업데이트를 안하면 2024-05-23 데이터를 조회할 수 없다.
아래와 같이 프로시저를 호출해주면 2024-05-23 데이터를 조회할 수 있다.
call refresh_continuous_aggregate('mv_minute', '2024-05-01', '2024-05-30');
call refresh_continuous_aggregate('MView 이름', window_start , window_end );
window_start부터 window_end까지 기간의 데이터를 refresh 해준다. 위의 예시로는 2024-05-01 ~ 2024-05-30 까지의 데이터를 refresh 한다.
그러면 아래와 같이 mv_minute에서 2024-05-23 데이터를 조회할 수 있다.
2) timescaledb.materialized_only 사용하기
MView를 생성할 때 argument에 "timescaledb.materialized_only = false"를 추가해준다.
CREATE MATERIALIZED VIEW mv_minute WITH (timescaledb.continuous, timescaledb.materialized_only = false) as
SELECT time_bucket('1 minute', data_date) as stats_date,
sum(a100.data_value) AS data_sum,
max(a100.data_value) AS data_max,
min(a100.data_value) AS data_min,
count(*) AS data_cnt,
first(data_date, data_date) as frist_data_date,
last(data_date, data_date) as last_data_date
FROM h_raw_data a100
GROUP BY stats_dt;
- - Index 생성
CREATE INDEX on mv_minute(stats_date, user_id);
h_raw_data에 새로운 데이터가 insert 되면 mv_minute에서 바로 조회가 가능하다.
하지만, 실시간으로 반영이 안될 때가 있다. mv_minute 테이블에서 가장 최근 시간 데이터 보다 과거 데이터를 insert를 하게 되면 반영이 안되는 것 같다. (되는 경우도 있는데, 기준이 어떤지 정확히 파악하지를 못했다)
공식 홈페이지에 따르면 이미 구체화된 버킷에 과거 데이터를 추가하면 반영이 안된다고 한다.
If you add new historical data to an already-materialized bucket, it won't be reflected in a real-time aggregate. You should wait for the next scheduled refresh, or manually refresh by calling refresh_continuous_aggregate. You can think of real-time aggregates as being eventually consistent for historical data.
이 문제를 해결하기 위해서 add_continuous_aggregate_policy를 적용해 주면 된다.
3) MView Job Policy 추가 (add_continuous_aggregate_policy)
Job으로 등록해 MView 데이터를 Update 해준다.
SELECT add_continuous_aggregate_policy(
'mv_minute'
, start_offset => INTERVAL '30 day'
, end_offset => INTERVAL '1 min'
, schedule_interval => INTERVAL '1 min'
, initial_start => now()
);
지금부터 Job을 시작해(initial_start) 1분 주기로(schedule_interval) 현재 시간에서 30일 전 데이터부터(start_offset) 현재 시간으로부터 1분 전 (end_offset) 기간 동안의 데이터를 다시 집계한다.
예를 들면 아래와 같이 데이터가 있고 오늘이 2024년 05월 25일 13:05:00.000 이라고 가정하자.

- "2024-04-30 13:00:00.000" 데이터를 insert 하면 30일 내의 데이터여서 mv_minute에서 조회가 가능하다.
- "2024-04-10 13:00:00.000" 데이터를 insert 하면 30일 범위 밖이여서 update 대상에 포함이 되지 않는다.
따라서, 해당 데이터는 mv_minute에서 조회할 수 없다. (start_offset 범위 밖)
- "2024-05-25 13:04:20.000" 데이터를 insert 하면 1분(end_offset) 내의 데이터여서 update 대상에 포함되지 않는다.
MView는 데이터를 생성해 메모리를 사용하고 있다. 그래서 꼭 아래와 같이 삭제 Job을 추가해야 한다.
select add_retention_policy(
'mv_minute',
drop_after => INTERVAL '90 days',
schedule_interval => INTERVAL '1 day',
initial_start => now()
);
지금부터(now()) 매일(schedule_interval) 90일 데이터를 제외하고 삭제한다(drop_after)
[느낀 점]
확실히 시간열 데이터는 Hyper Table을 사용하면 조회 속도가 빨라졌다.
기존 통계 조회 기능은 9~10초 걸렸는데 time_bucket으로 만든 MView는 1초 내로 조회가 됐다.
내가 사용하는 데이터의 성향(?)을 파악해서 DB를 고르는 것도 중요하다는 것을 느꼈다. 그리고 선택한 DB에서 제공해 주는 function을 많이 이용하자!!! (이미 최적화를 해놨기 때문에 이용하면 좋다.)
[참고]
Timescale documentation
Create a continuous aggregate on a hypertable or another continuous aggregate
docs.timescale.com
Timescale documentation
Add policy to schedule automatic refresh of a continuous aggregate
docs.timescale.com
'개발 > DB' 카테고리의 다른 글
| [DB] Timescaledb에서 PK와 Unique index 차이점 (0) | 2024.07.16 |
|---|---|
| [Timescaledb] Function, Procedure Job 스케줄러 등록 및 확인 방법 (0) | 2024.07.03 |
| [Postgresql] function return 값을 table로 보내기 (0) | 2024.07.03 |