728x90
트라이(Trie)
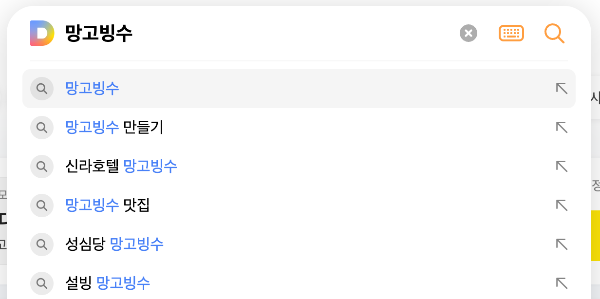
예를 들면 다음에서 검색어를 찾을 때 위 그림과 같이 연관된 단어를 찾아주거나, 자동 완성시켜줄 때 트라이(Trie) 자료구조를 사용한다.
즉, 트라이(Trie) 는 문자열을 저장하고 탐색하는데 유용한 트리 자료구조이다.
검색을 뜻하는 Retrieval의 중간 음절에서 따와 Trie라고 불린다. 또 다른 이름은 Redix Tree, Prefix Tree이다.
트라이(Trie)의 작동 원리
springboot, springcloud, spirngmvc, sports라는 문자열을 저장해보자. 그럼 아래와 같이 트리가 구성이 된다.
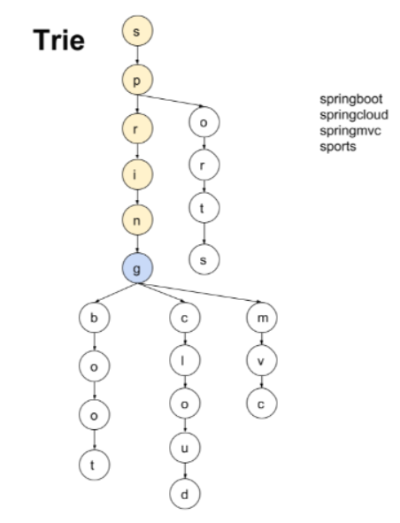
사전에서 단어를 찾을 때와 비슷하게 sports를 찾으면 s -> sp -> spo -> spor -> sport -> sports 이렇게 문자열을 찾습니다.
트라이(Trie)를 Java로 구현하기
전체 코드
package Trie;
import java.util.HashMap;
import java.util.Map;
public class TrieNode {
private Map<Character, TrieNode> childNodes = new HashMap<>();
private boolean isLastChar;
Map<Character, TrieNode> getChildNodes(){
return this.childNodes;
}
boolean isLastChar(){
return this.isLastChar;
}
void setIsLastChar(boolean isLastChar){
this.isLastChar = isLastChar;
}
}
package Trie;
public class Trie {
private TrieNode rootNode;
Trie(){
rootNode = new TrieNode();
}
public void insert(String word){
TrieNode thisNode = this.rootNode;
for(int i = 0; i < word.length(); i++){
thisNode = thisNode.getChildNodes().computeIfAbsent(word.charAt(i), chr -> new TrieNode());
}
thisNode.setIsLastChar(true);
}
public boolean contains(String word){
TrieNode thisNode = this.rootNode;
for(int i = 0; i < word.length(); i++){
char chr = word.charAt(i);
TrieNode node = thisNode.getChildNodes().get(chr);
if(node == null){
return false;
}
thisNode = node;
}
return thisNode.isLastChar();
}
public void delete(String word){
delete(this.rootNode, word, 0);
}
private void delete(TrieNode thisNode, String word, int index){
char chr = word.charAt(index);
if(!thisNode.getChildNodes().containsKey(chr)){
throw new Error("there is no [" + word + "] in this Trie");
}
TrieNode childNode = thisNode.getChildNodes().get(chr);
index += 1;
if(index == word.length()) {
if(!childNode.isLastChar())
throw new Error("there is no [" + word + "] in this Trie");
childNode.setIsLastChar(false);
if(childNode.getChildNodes().isEmpty())
thisNode.getChildNodes().remove(chr);
} else {
delete(childNode, word, index);
if(!childNode.isLastChar() && childNode.getChildNodes().isEmpty())
thisNode.getChildNodes().remove(chr);
}
}
}
메서드 설명
1. insert
- 입력받은 단어를 알파벳 한개씩 계층 구조의 자식노드로 만들어서 삽입한다.
- 이미 같은 알파벳이 존재하면 공통 접두어 부분까지는 추가로 생성하지 않는다. -> computeIfAbsent 활용
- 단어의 마지막 알파벳은 isLastChar에 true를 대입한다.
public void insert(String word){
TrieNode thisNode = this.rootNode;
for(int i = 0; i < word.length(); i++){
thisNode = thisNode.getChildNodes().computeIfAbsent(word.charAt(i), chr -> new TrieNode());
}
thisNode.setIsLastChar(true);
}
더보기
computeIfAbsent
- Map의 메서드
- 첫번째 파라미터에는 key를 두번째 파라미터에는 Function을 넣어준다.
- Map에 Key가 존재하지 않을때만 Function을 연산한 결과를 넣어준다.
2. contain
- 루트 노드부터 순서대로 알파벳이 일치하는 자식 노드들이 존재해야 한다.
- 해당 단어의 마지막 알파벳에 해당하는 노드의 isLastChar가 true인 것을 찾는다.
public boolean contains(String word){
TrieNode thisNode = this.rootNode;
for(int i = 0; i < word.length(); i++){
char chr = word.charAt(i);
TrieNode node = thisNode.getChildNodes().get(chr);
if(node == null){
return false;
}
thisNode = node;
}
return thisNode.isLastChar();
}
3. delete
- 탐색은 부모 노드에서 자식 노드의 방향이지만, 삭제는 자식 노드에서 부모 노드로 이루어 진다.
- 자식 노드를 가지고 있지 않아야 한다.
- 예를 들면, hi와 himart가 있을 경우 hi를 삭제할 때 hi를 삭제하면 himart도 삭제되가 때문이다.
- 삭제를 시작하는 첫 노드는 isLastChar == true이여야 한다. 자식 노드에서 부모 노드로 삭제되기 때문에 마지막 알파벳 부터 삭제해야 한다.
- 삭제 중 노드는 isLastChar == false 여야 합니다. 삭제중 true가 나오면 또 다른 단어가 있기 때문입니다.
public void delete(String word){
delete(this.rootNode, word, 0);
}
private void delete(TrieNode thisNode, String word, int index){
char chr = word.charAt(index);
if(!thisNode.getChildNodes().containsKey(chr)){
throw new Error("there is no [" + word + "] in this Trie");
}
TrieNode childNode = thisNode.getChildNodes().get(chr);
index += 1;
if(index == word.length()) {
if(!childNode.isLastChar())
throw new Error("there is no [" + word + "] in this Trie");
childNode.setIsLastChar(false);
if(childNode.getChildNodes().isEmpty())
thisNode.getChildNodes().remove(chr);
} else {
delete(childNode, word, index);
if(!childNode.isLastChar() && childNode.getChildNodes().isEmpty())
thisNode.getChildNodes().remove(chr);
}
}
백준 - 전화번호 목록 (Trie 활용)
[문제]
https://www.acmicpc.net/problem/5052
[풀이]
참고
[자료구조] Trie(트라이)에 대한 개념과 활용법
자료구조 Trie란? 일반적으로 트리의 개념 중 하나로, Radix Tree, Prefix Tree라고도 불립니다. 문자열의 자동 완성 기능과 같이 문자열을 저장하고 탐색하는데 유용한 자료구조입니다. ✅Trie의 형태
frtt0608.tistory.com
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] Set (Java) & HashSet이 정렬이 되는 이유 (0) | 2024.07.27 |
|---|---|
| [자료구조] B-Tree와 B+Tree의 질문 (1) | 2024.07.14 |
| [자료구조] B-Tree란? (1) | 2024.07.13 |
| [자료구조] 메모리관리 - 스택(Stack) 힙(Heap) (0) | 2023.04.01 |
| [자료구조] Array / ArrayList / LinkedList 특징 (0) | 2023.03.31 |